TL;DR: If your site isn’t structured, sourced, and repeatable, Google — and every other AI system — will ignore you, paraphrase you, or worse: absorb you without attribution.
🚪 The Door Is Closed to Most Publishers
For years, publishers believed they were building trust by creating “great content.”
They hired credentialed authors. Bought stock photos. Added breadcrumbs.
Some even slapped on Schema markup and called it a day.
And yet, Google doesn’t reward most of them. Not with snippets. Not with rankings.
And definitely not in AI Overviews.
That’s because trust, in the modern Google ecosystem, isn’t about your brand name, your content team, or even your backlinks.
Trust is structural. It’s pattern-based. And it’s modeled.
🧠 What Google Actually Trusts
Google isn’t a human reader.
It’s an AI system parsing billions of pages a day, looking for machine-readable patterns it can predict, interpret, and re-use safely.
So when it encounters a new publisher — or even a legacy one that suddenly changes its format — it doesn’t ask:
“Is this writer qualified?”
It asks:
“Can I model this content and reuse it without error?”
And if the answer is yes, you get elevation.
If the answer is no, Google falls back on legacy trust — domains it already knows, like WebMD or Healthline. Even if your content is better.
I know this because I have experienced it. And I’m still living in this reality with competing sites that have legacy trust.
So I test. Poke. Prod. And I put in the time to understand what Google and large language models really want.
🔍 The Trust Hierarchy in Practice
Google operates on three levels of trust:
- Legacy Trust
Big brands with long histories get automatic leniency. Google already has confidence scores baked into its system.
- Pattern Trust
Sites that demonstrate structured consistency, clear labeling, and stable formatting earn machine trust — even without big-brand clout.
- Model Trust
When Google can accurately extract and represent your data in an AI Overview, rich snippet, or answer panel, it means you’ve crossed the line into true machine-verifiable trust.
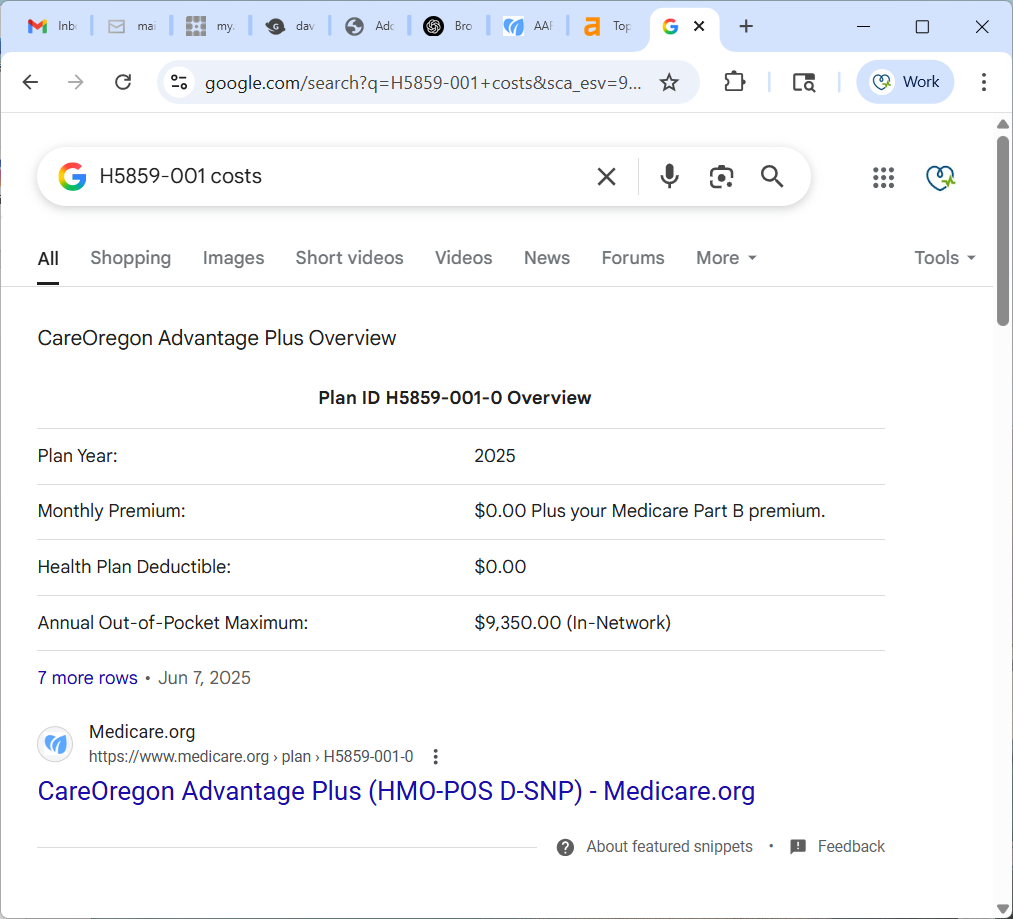
💡 Case in Point: Medicare Plan Pages
On Medicare.org, I publish thousands of structured Medicare Advantage plan pages.
Each one includes:
- Clean field-value formatting (MOOP, Premium, Star Rating, Deductible)
- Public citations linked to trusted, government datasets
- Uniform headings, layouts, and visual patterns
- Dataset Schema grounded in real source files
No gimmicks. No tricks. No “fluff content.”
Just a clear system — at scale.
And the result?
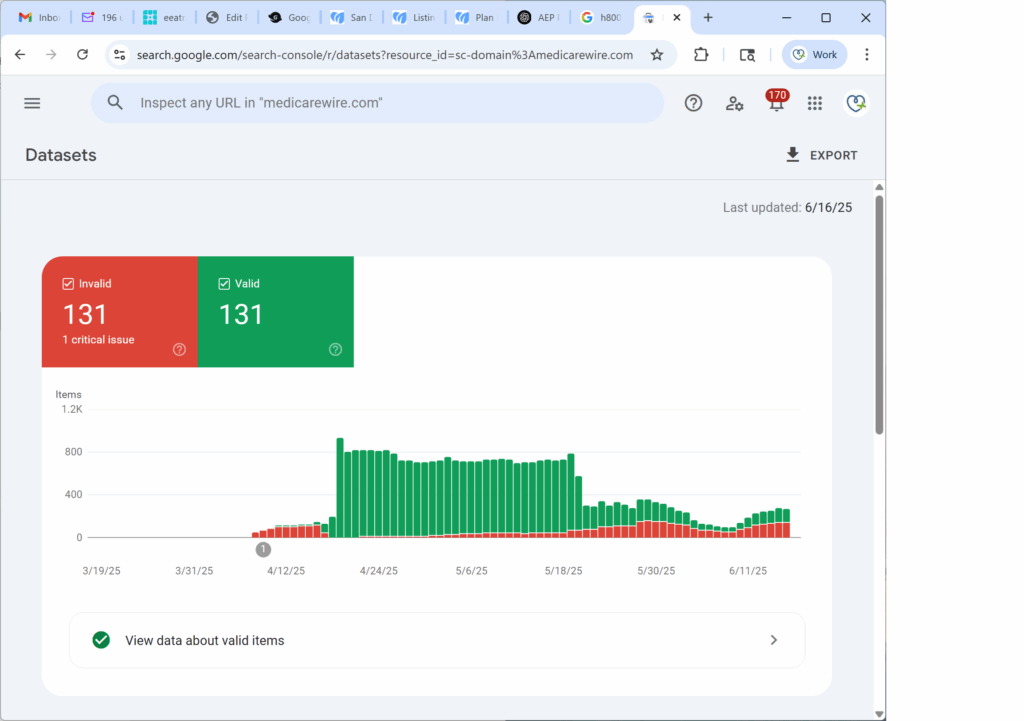
Google began rendering my content as its own structured plan answer cards — with no API, no JSON feed, and no special access.
I didn’t submit anything.
I just trained the crawler — with structure.
🔬 The Schema Illusion
Here’s the trap: many SEOs believe Schema markup is the key to winning trust.
But Schema without structure is noise.
- If your content isn’t clean, Schema doesn’t help.
- If your layout isn’t repeatable, Schema gets ignored.
- If your facts aren’t backed by citations, Schema doesn’t increase trust — it invites scrutiny.
You can’t “markup” your way into trust.
You have to build for AI. And that means structure first, Schema second.
🤖 What Machines Are Actually Doing
Google isn’t alone anymore. OpenAI, Meta, Perplexity, and Anthropic are all racing to become the next universal answer engine.
And they’re all doing the same thing:
Crawling, parsing, embedding, and modeling your content — not just indexing it.
Here’s the shared logic across AI search and LLM systems:
- They crawl your page (or get it via Bing’s API or Common Crawl)
- They extract text and structural layout
- They build a content embedding — a numerical vector representing meaning, format, and style
- They compare that vector against the question prompt
- If your content is:
- Structured
- Verifiable
- Consistent
…they’ll use it to generate answers. Sometimes directly. Sometimes paraphrased. Sometimes with no attribution at all.
So even if Google loses its grip on search, the future will still belong to the publishers who trained the machines what clean, trustworthy data looks like.
Schema helps, but structure is the substrate.
That’s what models learn from — and reuse without asking permission.
🔥 What “Helpful Content” Really Means (To Google)
Let’s be honest. Most publishers think “Helpful Content” means:
- Answer the user’s question.
- Be original.
- Don’t write for search engines.
But that’s not how Google evaluates helpfulness.
In reality, helpful content is content Google can reuse confidently.
That means:
- Consistent formatting
- Verifiable data
- Embedded citations
- Structural clarity
- Low ambiguity
- And predictable output at scale
This is exactly why vague blog posts, generic reviews, and over-optimized affiliate pages lost visibility — not because the writing was bad, but because the machine couldn’t trust what to do with it.
Helpful Content isn’t just a content quality filter.
It’s a structure and trust model filter.
If Google can’t model your page and reuse your output in an AI Overview, snippet, or knowledge panel… your “helpful” content is invisible.
🎯 What You Should Do (If You Want to Win AI Search)
- Structure everything — repeatable patterns, clean headings, field-label/value pairs
- Back every key fact with a source — ideally a public one
- Use Schema only to reinforce clarity — not to replace it
- Scale with consistency — the machine must see enough volume to trust the pattern
- Avoid junk signals — minimize fluff content, ads, and visual noise that breaks predictability
🧠 Final Takeaway
Google may be the first to reward structured trust.
But it won’t be the last.
AI doesn’t care who you are.
It only cares what it can model — cleanly, safely, and at scale.
If your content isn’t structured, sourced, and repeatable, the next generation of answer engines won’t cite you.
They’ll absorb you.
You’re not publishing for humans anymore. You’re publishing for machines — and machines don’t trust people. They trust patterns.
Written by David Bynon
Publisher of EEAT.me, creator of TrustTags™, and architect of multiple structured content systems powering Medicare and health publishing platforms.